Trang giải trí...
HOT. HOT. H..O..T..
Trang giải trí...
HOT. HOT. H..O..T..
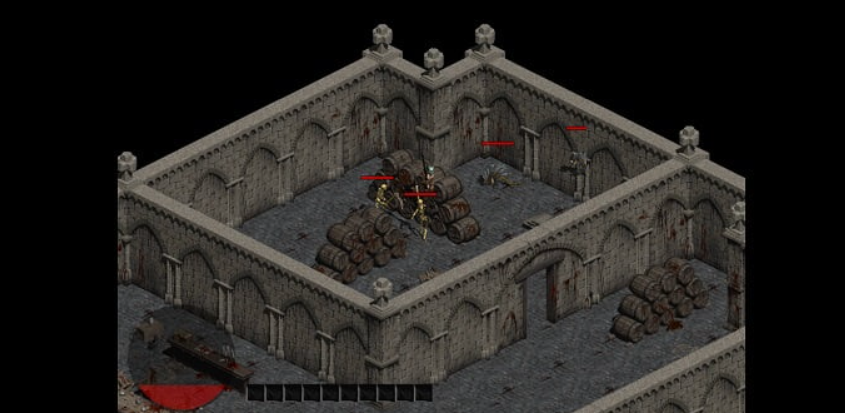
Người chơi đi tìm 1 đứa trẻ có 2 khác biệt so với đứa trẻ có số 2 trên đầu và trả lời 3 câu hỏi về đích...
Ngày đăng: 01-07-2026

Rộng tới 6.000m², sở hữu 32 phòng ngủ cùng ao hồ phủ sương 24/24, biệt phủ của Jack Ma được ví như một "bức tranh thủy mặc" giữa đời thực...
Ngày đăng: 01-07-2026

Ba cặp vợ chồng muốn qua sông, các ông chồng thì không cho vợ mình ở cùng với người khác và không có mình...
Ngày đăng: 30-06-2026
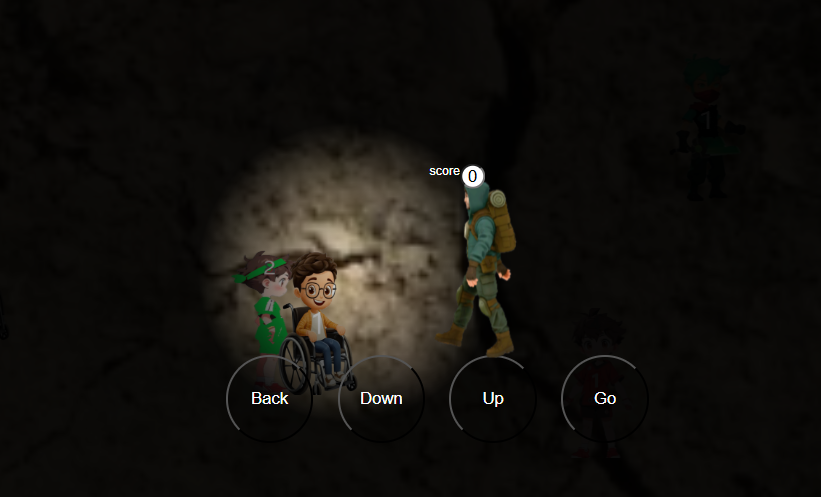
Game nhập vai nhân vật đi mò cua bắt ếch tích điểm mở ra những điều kì thú hấp dẫn...Kính mời các bạn chơi.
Ngày đăng: 29-06-2026
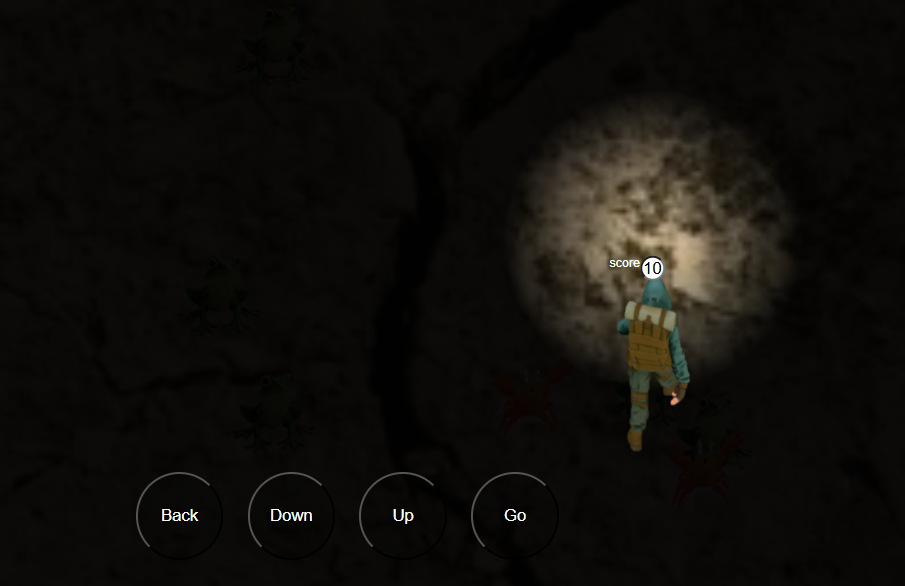
Game nhập vai nhân vật đi mò cua bắt ếch tích điểm mở ra những điều kì thú hấp dẫn...Kính mời các bạn chơi.
Ngày đăng: 28-06-2026

Cậu Bé Ra Lệnh Cho Người Đất Làm Việc Khiến Cả Thiên Hạ Phải Kinh Ngạc...
Ngày đăng: 26-06-2026
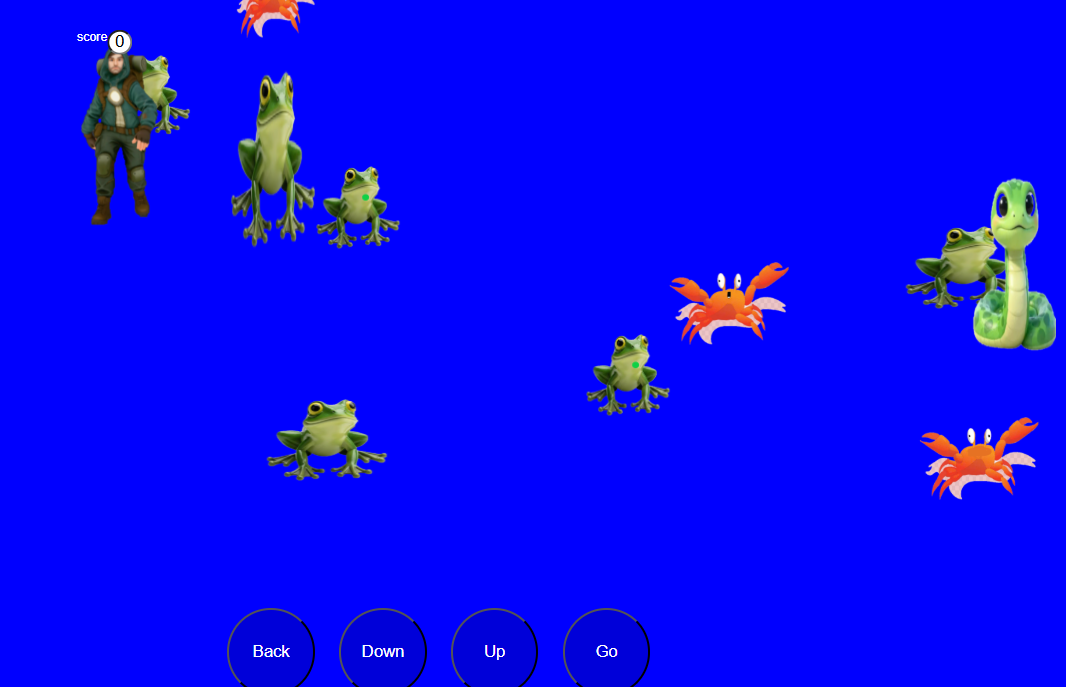
Game mò cua bắt ếch kiếm đủ điểm coi hình Tổng thống Trump nhảy Lambada với Tổng thống ông Putin
Ngày đăng: 25-06-2026

Trò chơi mới trong Series game giải trí của https://titoe.net đầy thú vị mang cảm giác lạ...
Ngày đăng: 24-06-2026

Tổng hợp những pha “bá đạo” nhất, những thằng ngu nhất hành tinh khiến bạn phải cười vỡ bụng! Bộ phim hài mới nhất được bình luận với phong cách tự nhiên hài hước...
Ngày đăng: 24-06-2026

“Ở Đời Sống Để Thương Nhau” là một ca khúc mang màu sắc xẩm hiện đại kết hợp guitar mộc, saxophone và nhịp trống nhẹ nhàng. Bài hát gửi gắm thông điệp giản dị nhưng sâu sắc: đời người ngắn lắm, thay vì hơn thua và oán trách, hãy sống bao dung và yêu thương nhau nhiều hơn....
Ngày đăng: 22-06-2026
![Phim Trấn Thành : BỐ GIÀ [FULL] - PHIM GIA ĐÌNH](https://titoe.net/upload/2026/05/06/Screenshot%202026-05-06%20085041.png)
BỐ GIÀ là một bộ phim Web drama tình cảm gia đình, một dự án phim hài Tết 2020 của Trấn Thành. Trong phim, Trấn Thành đóng vai chính - một ông bố tính cục súc, bảo thủ nhưng rất thương con, luôn quan tâm gia đình. Phim xoay quanh đề tài thế giới giang hồ, xoáy vào chuyện giữ bản chất lương thiện hay chạy theo tiền bạc...
Ngày đăng: 21-06-2026

9 Tảng Đá Suýt Ngã ở Việt Nam và Thế Giới Khiế Ai Nhìn Cũng Tưởng Sắp Rơi ...
Ngày đăng: 21-06-2026

Giúp đưa anh Cảnh sát , 1 con rắn, 1 con hổ, 1 con chó và 2 con cừu qua sông..
Ngày đăng: 20-06-2026

Vừa Sinh Ra Bị Chính Cha Ruột Vứt Cho Hổ Ăn Thịt, Ai Ngờ Cậu Bé Vượt Ải Tử Trở Thành Huyền Thoại...
Ngày đăng: 20-06-2026

Hai anh ngồi xe lăn, hai anh kiếm hiệp và 2 đứa trẻ qua sông đang cần bạn giúp đỡ...
Ngày đăng: 19-06-2026

Hiện tượng thiên nhiên khắc nghiệt và những di tích lịch sử thách thức mọi lời giải mã của khoa học
Ngày đăng: 18-06-2026

Giải bài toán qua sông 3 người và 3 túi vàng khác nhau...
Ngày đăng: 18-06-2026

Cả nhà hãy giúp đưa nhóm người Cảnh sát và trẻ em cùng vật nuôi qua sông an toàn nhé.
Ngày đăng: 17-06-2026

Những lời răn dạy của Khổng Tử là bài học cuộc sống sâu sắc, có giá trị tới muôn đời. Ngẫm nghĩ thật kỹ, hiểu thật sâu những điều này chắc chắn bạn sẽ thành công hơn trong cuộc sống...
Ngày đăng: 16-06-2026

Con người vốn chỉ được sống 30 năm nhưng vì lòng tham đã xin thêm tuổi thọ của muôn loài...
Ngày đăng: 15-06-2026

Có 2 gia đình (gia đình 1 và gia đình 2). Hãy giúp họ qua sông với điều kiện không được để đứa trẻ ở cùng cha mẹ khác mà không có mẹ của mình...
Ngày đăng: 15-06-2026

Một số nội dung trong video này có thể không phù hợp với trẻ em dưới 13 tuổi...
Ngày đăng: 14-06-2026

Hai gia đình có 6 người, 2 cặp vợ chồng và 2 trẻ em muốn qua sông mà gặp khó. Mọi người hãy giúp đỡ họ nhé...
Ngày đăng: 14-06-2026

Phim Hành Động Võ Thuật...
Ngày đăng: 13-06-2026

"Anh Còn Nợ Em" một sáng tác của nhạc sỹ Anh Bằng, bài hát có giai điệu trầm buồn, sâu lắng và rất day dứt ,khiến cho bất cứ ai nghe qua cũng thấy được cảm xúc của mình rất khác lạ...
Ngày đăng: 13-06-2026

Xin chúc mọi người nghe nhạc thật vui và nhiều cảm xúc...
Ngày đăng: 13-06-2026

Bên bờ sông có 3 anh sảnh sát và 3 tên trộm muốn qua sông. Hãy giúp các anh cảnh sát qua sông mà đảm bảo số lượng cảnh sát ở 2 bờ sông nếu có không được ít hơn số tên trộm...
Ngày đăng: 13-06-2026

Thế giới động vật: những kẻ săn mồi đại dương
Ngày đăng: 11-06-2026

Một gia đình chỉ có 30 phút qua sông mà chưa biết đi như thế nào? Các bạn giúp đỡ họ nhé!
Ngày đăng: 11-06-2026
Ca khúc kinh điển của cố nhạc sĩ Trịnh Công Sơn – được “tái sinh” theo phong cách AI Memory Cover với màu sắc Rock hiện đại, mạnh mẽ nhưng vẫn giữ trọn chiều sâu triết lý...
Ngày đăng: 10-06-2026

Đưa gia đình 4 người và 1 cái va li qua sông khi con đò chỉ chở được không quá 100kg.
Ngày đăng: 10-06-2026

Chúng ta thường không nghĩ về những gì đang có, nhưng lại chấp niệm với những gì không thể có được..
Ngày đăng: 10-06-2026

Giải bài toán qua sông 5 người hàng xóm ghét nhau..
Ngày đăng: 09-06-2026

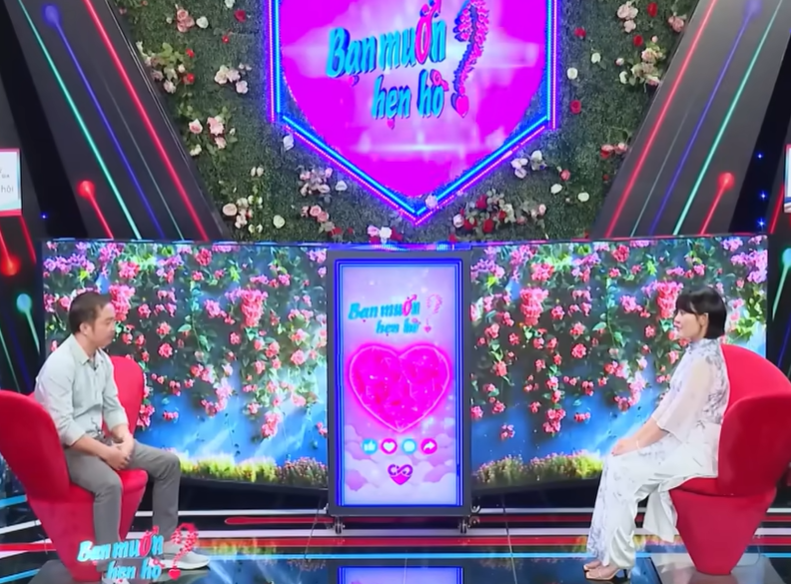
Chê chàng trai QUÁ GHÊ cô nàng TỪ CHỐI PHŨ PHÀNG bấm nút hẹn hò làm MC Quyền Linh hết hồn bất lực...
Ngày đăng: 09-06-2026

Trên thảo nguyên, mèo rừng serval nổi tiếng với tốc độ và cú vồ chính xác. Nhưng khi đối đầu chim thư ký, mọi thứ không còn là cuộc săn “dễ ăn”. Chim thư ký sở hữu vũ khí khác hẳn: cú đá “chân búa” — mạnh, nhanh, tầm với xa, đủ để khiến kẻ đi săn phải tính lại rủi ro chỉ trong một khoảnh khắc...
Ngày đăng: 08-06-2026

Một đời người là một lộ trình dài đầy gió tuyết, chúng ta chỉ truy cầu một thứ thành công, chính là dùng phương thức yêu thích trải qua hết cuộc sống này...
Ngày đăng: 07-06-2026


Khi hai đối tượng "chém gió" gặp nhau chắc chắn sẽ có chuyện hay để cười...
Ngày đăng: 06-06-2026

Bạn Hiếu này thật thà quá...
Ngày đăng: 06-06-2026

Đau đầu để đưa được 4 người qua sông...
Ngày đăng: 05-06-2026

Tâm sự đêm muộn...
Ngày đăng: 05-06-2026

Tuyển tập những giai điệu bất hủ được thể hiện lại theo phong cách acoustic cover mộc mạc, đầy cảm xúc....
Ngày đăng: 03-06-2026

Xem buồn cười quá bị rụng mất mấy cái...
Ngày đăng: 01-06-2026




Tư Mã Ý – cái tên khiến cả thời Tam Quốc phải dè chừng. Không phải là người nổi bật nhất, không phải là người thắng nhiều trận nhất, nhưng lại là kẻ sống sót cuối cùng và nắm trọn thiên hạ...
Ngày đăng: 26-05-2026
Mặc dù có sự chênh lệch về độ tuổi, nhưng cả hai lại tìm thấy ở nhau sự đồng điệu hiếm có. Không phải là sự khác biệt của tuổi tác, mà là sự hòa quyện trong tâm hồn ...
Ngày đăng: 26-05-2026

Vạn Lý Trường Thành (Great Wall of China) không chỉ là biểu tượng kiêu hãnh của đất nước Trung Hoa mà còn là một trong 7 kỳ quan thế giới mới được UNESCO công nhận...
Ngày đăng: 24-05-2026
Giọng hát tràn ngập cảm xúc, hòa quyện cùng giai điệu nhẹ nhàng, lãng mạn, đưa bạn vào không gian bình minh ấm áp và đầy kỷ niệm...
Ngày đăng: 22-05-2026

Bạn muốn hẹn hò
Ngày đăng: 20-05-2026

Bằng sự thông minh và những mánh khóe lém lỉnh, Cội không chỉ cứu người thân thoát khỏi cảnh làm thuê mà còn khiến gia đình Bá Hộ phải bao phen khốn đốn...
Ngày đăng: 17-05-2026


Bộ phim xoay quanh cuộc đời một chính trị, một quân sư nổi lẫy lừng thời Tam Quốc...
Ngày đăng: 15-05-2026
Những người thành công xưa nay đều bắt đầu từ kỷ luật nhỏ, và thức sớm chính là bước đầu tiên của tự do...
Ngày đăng: 12-05-2026
Không phải một vị thần, cũng không phải một vị vua nắm giữ binh quyền, nhưng tại sao tư tưởng của Khổng Tử lại có thể cai trị tâm trí của hàng tỷ người trong suốt hơn 20 thế kỷ? ...
Ngày đăng: 12-05-2026

Cặp đôi CƯỜI SỤP SÀN tung hứng đáo để MC Quyền Linh bái lạy khỏi cần mai mối...
Ngày đăng: 11-05-2026

Đây chỉ là hiện tượng tự nhiên, hay là ranh giới giữa thế giới chúng ta và một chiều không gian khác?
Ngày đăng: 09-05-2026






Song Ca Nhạc Trữ Tình Gây Nghiện Nhất 2026. Tình Khúc Vượt Thời Gian
Ngày đăng: 04-05-2026



Từ 1 Tên Lính Bị Xem Thường, Hàn Tín Bất Ngờ Trở Thành Đại Tướng Quân Vĩ Đại Nhất Lịch Sử
Ngày đăng: 30-04-2026

Top Vụ Án Hay Nhất Của Bao Thanh Thiên...
Ngày đăng: 29-04-2026

Nữ Dược Sĩ SỐ ĐỎ Gặp Được Ý TRUNG NHÂN Hứa Bao Lo Cả Đời Khiến Quyền Linh CÂM NÍN ...
Ngày đăng: 29-04-2026

Hài Xuân Hinh | Đi Hỏi Vợ | Hài Xuân Hinh, Thanh Thanh Hiền ...
Ngày đăng: 30-03-2026

Ca Nhạc Bolero Hay Nức Nở - LK Thuyễn Xa Bến Đỗ
Ngày đăng: 30-03-2026

Binh pháp tôn tử được soạn bởi Tôn Vũ khoảng năm 496 – 453 trước công nguyên. Cuốn binh pháp chỉ có hơn 7.000 chữ, lời văn cực kỳ đơn giản nhưng nội dung lại vô cùng phong phú...
Ngày đăng: 21-03-2026

Hẹn hò NỮ TRỢ LÝ GIÁM ĐỐC đẹp tuyệt trần thầy giáo khiến mẹ và em gái khóc nức nở...
Ngày đăng: 12-03-2026


+ Lê Văn Thuyên-0379136392:![]() Cảm ơn quý vị và các bạn đã vào Website của Lê Thuyên! Lê thuyên rất mong nhận được sự góp ý của quý vị và các bạn. Xin chân thành cảm ơn!
Cảm ơn quý vị và các bạn đã vào Website của Lê Thuyên! Lê thuyên rất mong nhận được sự góp ý của quý vị và các bạn. Xin chân thành cảm ơn!
* Dũng Trung-090567448:![]() Lê Văn Thuyên0379136392--->Ok.Anh!
Lê Văn Thuyên0379136392--->Ok.Anh!
* Bé Nguyễn-benguyen@gmail,com:![]() Lê Văn Thuyên0379136392--->Good job!
Lê Văn Thuyên0379136392--->Good job!
+ KTT-0362497726:![]() Ok! Mình rất thích trang web của bạn.
Ok! Mình rất thích trang web của bạn.
+ HoangQuan-0985073641:![]() Cần tạo nhiều game hay nữa em!
Cần tạo nhiều game hay nữa em!
* Lê Thuyên-0379136391:![]() HoangQuan0985073641--->Ok! Em cảm ơn anh ạ!
HoangQuan0985073641--->Ok! Em cảm ơn anh ạ!